YourAIrunsonyourinfrastructure.Yourdataneverleavesit.
9 providers, 20+ models, 3 sovereignty levels. The router automatically selects the right model based on data sensitivity. SkaLean configures and maintains the infrastructure. You use it.
Three levels, one router
The LLM router automatically selects the right level based on data sensitivity. No action required from the user.

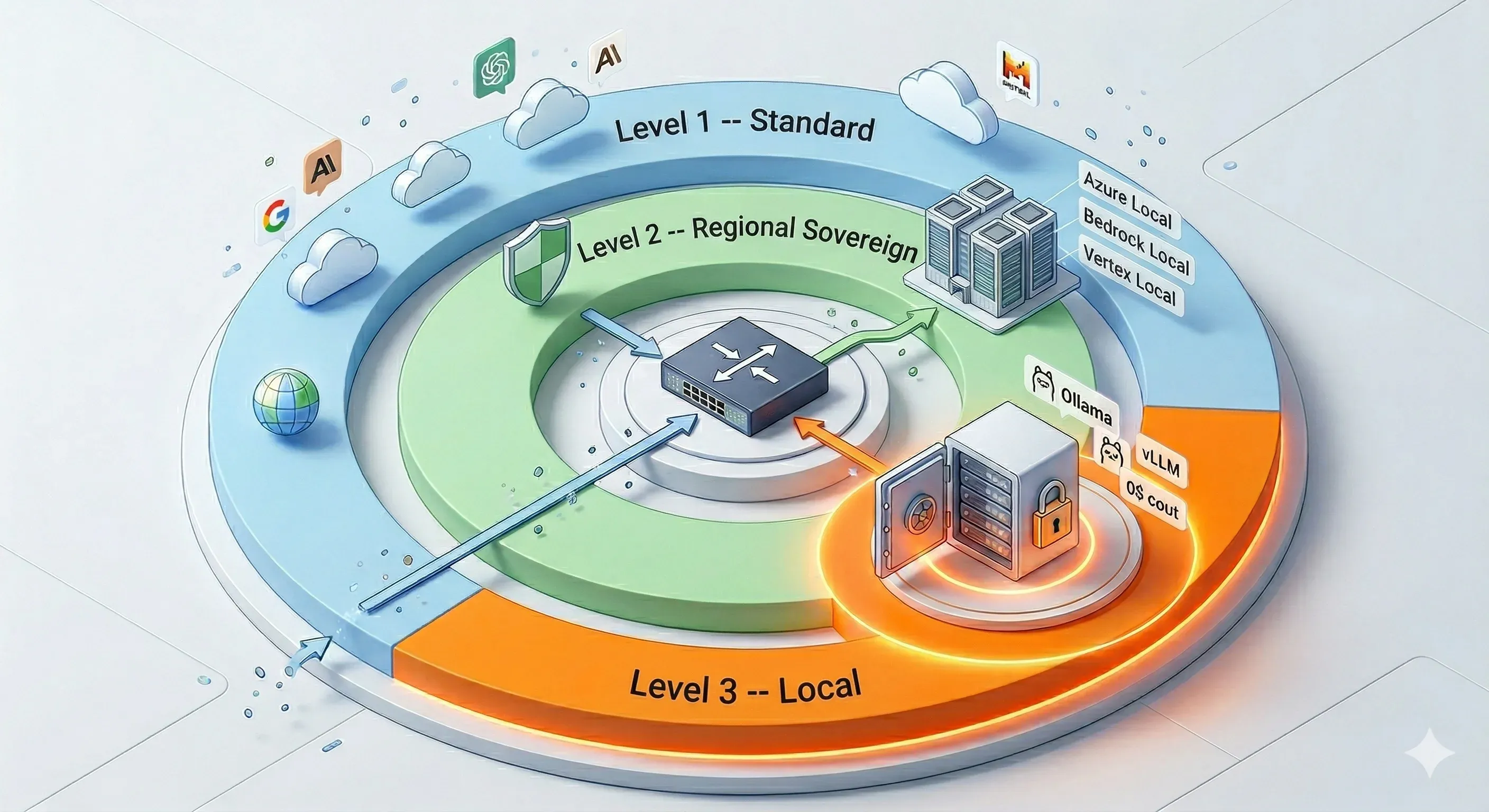
The router decides, you do nothing
4-step routing algorithm. No manual configuration. Automatic fallback if preferred model is unavailable.
The most complete AI engine
Built for teams with compliance requirements who won't sacrifice performance.
6 steps from your document to the answer
Target: under 800ms P95. Each step is independent, observable, and auditable.
Sovereign GPU: 2–4x faster
Optimized sovereign GPU inference. Our engine accelerates throughput to multiply performance without leaving your infrastructure.
No competitor combines all 3 tiers
OpenAI, Azure, and Mistral each offer a piece of the puzzle. SkaLean is the only AI engine that integrates them all, with automatic routing, sovereign GPU, native RAG, and zero commission.
| Criterion | OpenAI / Anthropic API | Azure OpenAI · Bedrock · Vertex | Open-source DIY | SkaLean AI Engine |
|---|---|---|---|---|
| Data sovereignty | — US servers | ✓ Region of choice | ✓ On your infrastructure | ✓ 3 automatic tiers |
| Number of providers / models | 1 provider | 1-2 providers | Free models only | ✓ 9 providers · 20+ models |
| Automatic PII routing | — | — | — | ✓ 15 types · sensitivity score |
| PII protection before LLM send | — | — | — | ✓ Pseudonymization + re-substitution |
| TensorRT-LLM (2-4x acceleration) | — | — | Complex DIY | ✓ Native · no competing AIaaS |
| LoRA fine-tuning per client (NeMo) | OpenAI fine-tuning (expensive) | Azure fine-tuning (expensive) | DIY · no client isolation | ✓ NeMo · encrypted dataset · isolated |
| Sovereign medical model | — | — | — | ✓ Outperforms general models on health data |
| Integrated 6-step RAG | — | — | DIY · no turnkey pipeline | ✓ Hybrid + RRF + reranking + citations |
| Breaker + automatic fallback | — | — | — | ✓ Automatic cascade fallback · 5 retries |
| OWASP LLM Top 10 | Basic | Partial | — | ✓ 10/10 · non-disableable |
| Activatable HIPAA compliance | — | ✓ BAA available (Azure, AWS) | — Manual configuration required | ✓ Client-activatable HIPAA compliance |
| Token commission | Public rate | Public rate + regional markup | DIY infrastructure cost | 0% Exact provider rate |
| Managed service | — Self-service | — Self-service | — Everything to configure | ✓ Building · maintenance · SkaLean expertise |
Your data never leaves your region
Local infrastructure · native regulatory compliance · GDPR + CCPA · HIPAA activatable per tenant. SkaLean configures and maintains your sovereign infrastructure.
Frequently asked questions
The AI Engine powers the entire ecosystem
The sovereign AI Engine is the brain powering AI Studio, AI Automation, and AI Assistants, locally hosted, compliant with your regulations, zero imposed cloud dependency.
You pay for tokens. Nothing more.
SkaLean takes zero commission on LLM calls. You're billed exactly at the provider's published rate.
| Provider | Model | Input / 1K tokens | Output / 1K tokens | Notes |
|---|---|---|---|---|
| OpenAI | gpt-4o | 0,0025 $ | 0,01 $ | 128K context · Tool calling |
| OpenAI | gpt-4o-mini | 0,00015 $ | 0,0006 $ | Ultra fast · economical |
| OpenAI | gpt-4.1 / gpt-4.1-mini | 0,002 $ / 0,0001 $ | 0,008 $ / 0,0004 $ | Latest generation |
| Anthropic | claude-opus-4 | 0,015 $ | 0,075 $ | 200K context · reasoning |
| Anthropic | claude-sonnet-4 | 0,003 $ | 0,015 $ | Balanced performance/cost |
| Anthropic | claude-haiku-4.5 | 0,00025 $ | 0,00125 $ | Very fast · low cost |
| Mistral | mistral-large-2 | 0,002 $ | 0,006 $ | European hosting (Paris) |
| Mistral | mistral-small-3.1 | 0,0002 $ | 0,0006 $ | Compact European model |
| gemini-2.5-pro | 0,00125 $ | 0,005 $ | Very long context | |
| gemini-2.5-flash | 0,00015 $ | 0,0006 $ | Ultra fast · streaming |
| Platform | Model | Input / 1K tokens | Output / 1K tokens | Sovereignty |
|---|---|---|---|---|
| Azure OpenAI | gpt-4o / gpt-4o-mini | 0,0025 $ / 0,00015 $ | 0,01 $ / 0,0006 $ | Sovereign region of your choice |
| Azure OpenAI | gpt-4.1 / gpt-4.1-mini | 0,002 $ / 0,0001 $ | 0,008 $ / 0,0004 $ | Data remain in your country |
| AWS Bedrock | Claude Opus 4 / Sonnet 4 | 0,015 $ / 0,003 $ | 0,075 $ / 0,015 $ | Sovereign Bedrock region |
| AWS Bedrock | Llama 3.1 70B / 8B | 0,00065 $ / 0,0003 $ | 0,00085 $ / 0,0006 $ | Open model via Bedrock |
| Vertex AI | Gemini 2.5 Pro / Flash | 0,00125 $ / 0,00015 $ | 0,005 $ / 0,0006 $ | Sovereign Vertex region |
| Vertex AI | Claude Sonnet 4 (via Vertex) | 0,003 $ | 0,015 $ | Anthropic via Google Model Garden |
| Infrastructure | Models | Input / 1K tokens | Output / 1K tokens | Conditions |
|---|---|---|---|---|
| Ollama CPU | Llama, Mistral, Qwen and open-source models | 0 $ | 0 $ | Included in all plans |
| GPU Inference | Llama 70B+, Qwen 72B, specialized medical models | Billed at usage | Billed at usage | Configured by SkaLean · included in onboarding |
| Custom LLM | NeMo LoRA fine-tuning on your data | included in onboarding | included in onboarding | Enterprise plan |
Your AI infrastructure, managed by SkaLean.
9 providers, 20+ models, 3 sovereignty levels. Deployment in 5 to 20 days.