VotreIAtournesurvotreinfrastructure.Vosdonnéesnelaquittentjamais.
9 fournisseurs, 20+ modèles, 3 niveaux de souveraineté. Le routeur choisit automatiquement le bon modèle selon la sensibilité de vos données. SkaLean configure et maintient l’infrastructure. Vous utilisez.
Trois niveaux, un seul routeur
Le routeur LLM choisit automatiquement le bon niveau selon la sensibilité des données. Aucune action requise de l’utilisateur.

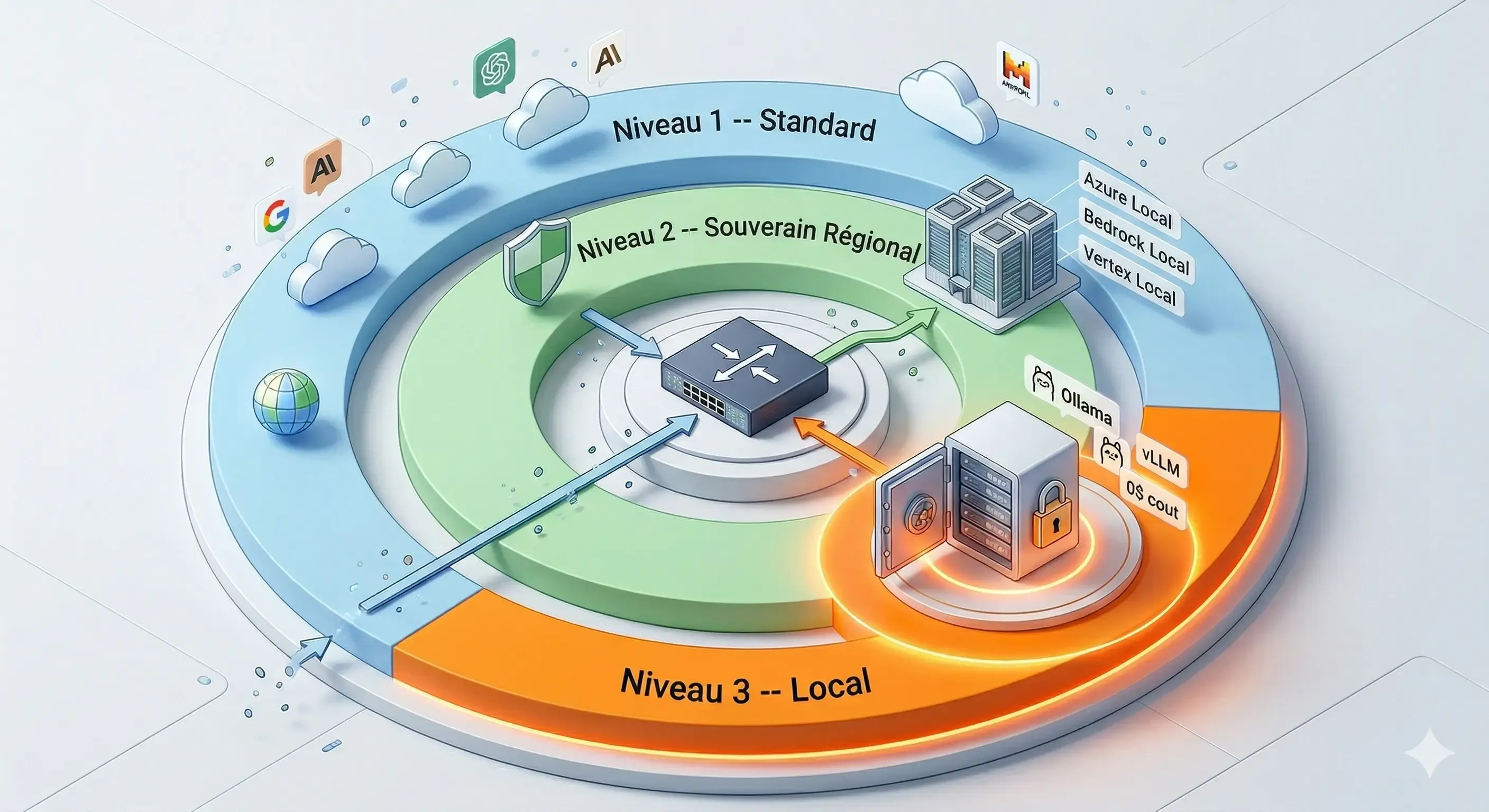
Le routeur choisit, vous n’avez rien à faire
Algorithme de routage en 4 étapes. Aucune configuration manuelle. Repli automatique si le modèle préféré est indisponible.
Le moteur IA le plus complet
Conçu pour les équipes qui ont des exigences de conformité sans vouloir sacrifier la performance.
6 étapes de votre document à la réponse
Cible : moins de 800ms P95. Chaque étape est indépendante, observable et auditable.
GPU souverain : 2–4x plus rapide
Inférence souveraine optimisée sur GPU. Notre moteur accélère le débit pour multiplier les performances sans quitter votre infrastructure.
Aucun concurrent ne combine les 3 tiers
OpenAI, Azure et Mistral proposent chacun une pièce du puzzle. SkaLean est le seul moteur IA qui les intègre tous, avec routage automatique, GPU souverain, RAG natif et zéro commission.
| Critère | OpenAI / Anthropic API | Azure OpenAI · Bedrock · Vertex | Open-source DIY | SkaLean Moteur IA |
|---|---|---|---|---|
| Souveraineté des données | — Serveurs US | ✓ Région au choix | ✓ Sur votre infra | ✓ 3 tiers automatiques |
| Nombre de fournisseurs / modèles | 1 fournisseur | 1-2 fournisseurs | Modèles libres seulement | ✓ 9 fournisseurs · 20+ modèles |
| Routage automatique PII | — | — | — | ✓ 15 types · score de sensibilité |
| Protection PII avant envoi LLM | — | — | — | ✓ Pseudonymisation + re-substitution |
| TensorRT-LLM (accélération 2-4x) | — | — | DIY complexe | ✓ Natif · aucun AIaaS concurrent |
| Affinage LoRA par client (NeMo) | Affinage OpenAI (coûteux) | Affinage Azure (coûteux) | DIY · aucune isolation client | ✓ NeMo · jeu de données chiffré · isolé |
| Modèle médical souverain | — | — | — | ✓ Surpasse les modèles généralistes sur données de santé |
| RAG 6 étapes intégré | — | — | DIY · pas de pipeline clé-en-main | ✓ Hybride + RRF + reclassement + citations |
| Disjoncteur + repli automatique | — | — | — | ✓ Repli automatique en cascade · 5 tentatives |
| OWASP LLM Top 10 | Basique | Partiel | — | ✓ 10/10 · non désactivable |
| Conformité HIPAA activable | — | ✓ BAA disponible (Azure, AWS) | — Manuel à configurer | ✓ Conformité HIPAA activable par client |
| Commission sur tokens | Tarif public | Tarif public + surcoût région | Coût infra DIY | 0% Tarif fournisseur exact |
| Service géré | — Libre-service | — Libre-service | — Tout à configurer | ✓ Construction · maintenance · expertise SkaLean |
Vos données ne quittent jamais votre région
Infrastructure locale · conformité réglementaire native · RGPD · CCPA · HIPAA activable par locataire. SkaLean configure et maintient votre infrastructure souveraine.
Ce que ChatGPT ne peut pas faire pour votre PME
ChatGPT est un outil générique. Studio IA SkaLean est un expert de votre secteur, hébergé chez vous.
| Ce qui compte pour votre PME | ChatGPT / Microsoft Copilot | Studio IA SkaLean |
|---|---|---|
| Répond depuis... | Internet public (risque de contenu inexact) | Vos documents uniquement |
| Vos données envoyées aux États-Unis ? | Oui — serveurs OpenAI / Microsoft | Jamais — infrastructure souveraine |
| Modèle entraîné sur votre secteur ? | Non — modèle généraliste | Oui — fine-tuning LoRA sectoriel |
| Conformité RGPD / HIPAA native ? | Partielle — dépend du contrat MSA | Oui — certifiée et auditable |
| Traces et audit des requêtes ? | Non — boite noire | Oui — 100 % traçable |
| Isolation de vos données des autres clients ? | Non — mutualisé | Oui — conteneur dédié par client |
| Intégré à vos outils existants ? | Limité (API manuelle) | Oui — 200+ connecteurs natifs |
Questions fréquentes
Le Moteur IA alimente tout l’écosystème
Le Moteur IA souverain est le cerveau qui propulse Studio IA, Automatisation IA et les Assistant IA, hébergé localement, conforme à votre réglementation, zéro dépendance cloud imposée.
Vous payez les tokens. Rien de plus.
SkaLean ne prend aucune commission sur les appels LLM. Vous êtes facturés exactement au tarif publié par le fournisseur.
| Fournisseur | Modèle | Entrée / 1K tokens | Sortie / 1K tokens | Notes |
|---|---|---|---|---|
| OpenAI | gpt-4o | 0,0025 $ | 0,01 $ | 128K contexte · Tool calling |
| OpenAI | gpt-4o-mini | 0,00015 $ | 0,0006 $ | Ultra rapide · économique |
| OpenAI | gpt-4.1 / gpt-4.1-mini | 0,002 $ / 0,0001 $ | 0,008 $ / 0,0004 $ | Dernière génération |
| Anthropic | claude-opus-4 | 0,015 $ | 0,075 $ | 200K contexte · raisonnement |
| Anthropic | claude-sonnet-4 | 0,003 $ | 0,015 $ | Équilibre performance/coût |
| Anthropic | claude-haiku-4.5 | 0,00025 $ | 0,00125 $ | Très rapide · faible coût |
| Mistral | mistral-large-2 | 0,002 $ | 0,006 $ | Hébergement européen (Paris) |
| Mistral | mistral-small-3.1 | 0,0002 $ | 0,0006 $ | Modèle européen compact |
| gemini-2.5-pro | 0,00125 $ | 0,005 $ | Très long contexte | |
| gemini-2.5-flash | 0,00015 $ | 0,0006 $ | Ultra rapide · diffusion en continu |
| Plateforme | Modèle | Entrée / 1K tokens | Sortie / 1K tokens | Souveraineté |
|---|---|---|---|---|
| Azure OpenAI | gpt-4o / gpt-4o-mini | 0,0025 $ / 0,00015 $ | 0,01 $ / 0,0006 $ | Région souveraine de votre choix |
| Azure OpenAI | gpt-4.1 / gpt-4.1-mini | 0,002 $ / 0,0001 $ | 0,008 $ / 0,0004 $ | Données restent dans votre pays |
| AWS Bedrock | Claude Opus 4 / Sonnet 4 | 0,015 $ / 0,003 $ | 0,075 $ / 0,015 $ | Région Bedrock souveraine |
| AWS Bedrock | Llama 3.1 70B / 8B | 0,00065 $ / 0,0003 $ | 0,00085 $ / 0,0006 $ | Modèle ouvert via Bedrock |
| Vertex AI | Gemini 2.5 Pro / Flash | 0,00125 $ / 0,00015 $ | 0,005 $ / 0,0006 $ | Région Vertex souveraine |
| Vertex AI | Claude Sonnet 4 (via Vertex) | 0,003 $ | 0,015 $ | Anthropic via Google Model Garden |
| Infrastructure | Modèles | Entrée / 1K tokens | Sortie / 1K tokens | Conditions |
|---|---|---|---|---|
| Ollama CPU | Llama, Mistral, Qwen et modèles open-source | 0 $ | 0 $ | Inclus dans tous les plans |
| Inférence GPU | Llama 70B+, Qwen 72B, modèles médicaux spécialisés | Facturés à l’usage | Facturés à l’usage | Service configuré par SkaLean · inclus mise en service |
| LLM custom | Affinage NeMo LoRA sur vos données | inclus mise en service | inclus mise en service | Plan Enterprise |
Votre infrastructure IA, gérée par SkaLean.
9 fournisseurs, 20+ modèles, 3 niveaux de souveraineté. Déploiement en 5 à 20 jours.