ذكاؤكالاصطناعييعملعلىبنيتكالتحتية.بياناتكلاتغادرهاأبدًا.
9 مزودين، 20+ نموذج، 3 مستويات سيادة. يختار الموجِّه النموذج المناسب تلقائيًا بناءً على حساسية البيانات. SkaLean تضبط البنية التحتية وتديرها. أنت تستخدمها.
ثلاثة مستويات، موجِّه واحد
يختار موجِّه LLM المستوى الصحيح تلقائيًا بناءً على حساسية البيانات. لا يلزم أي إجراء من المستخدم.

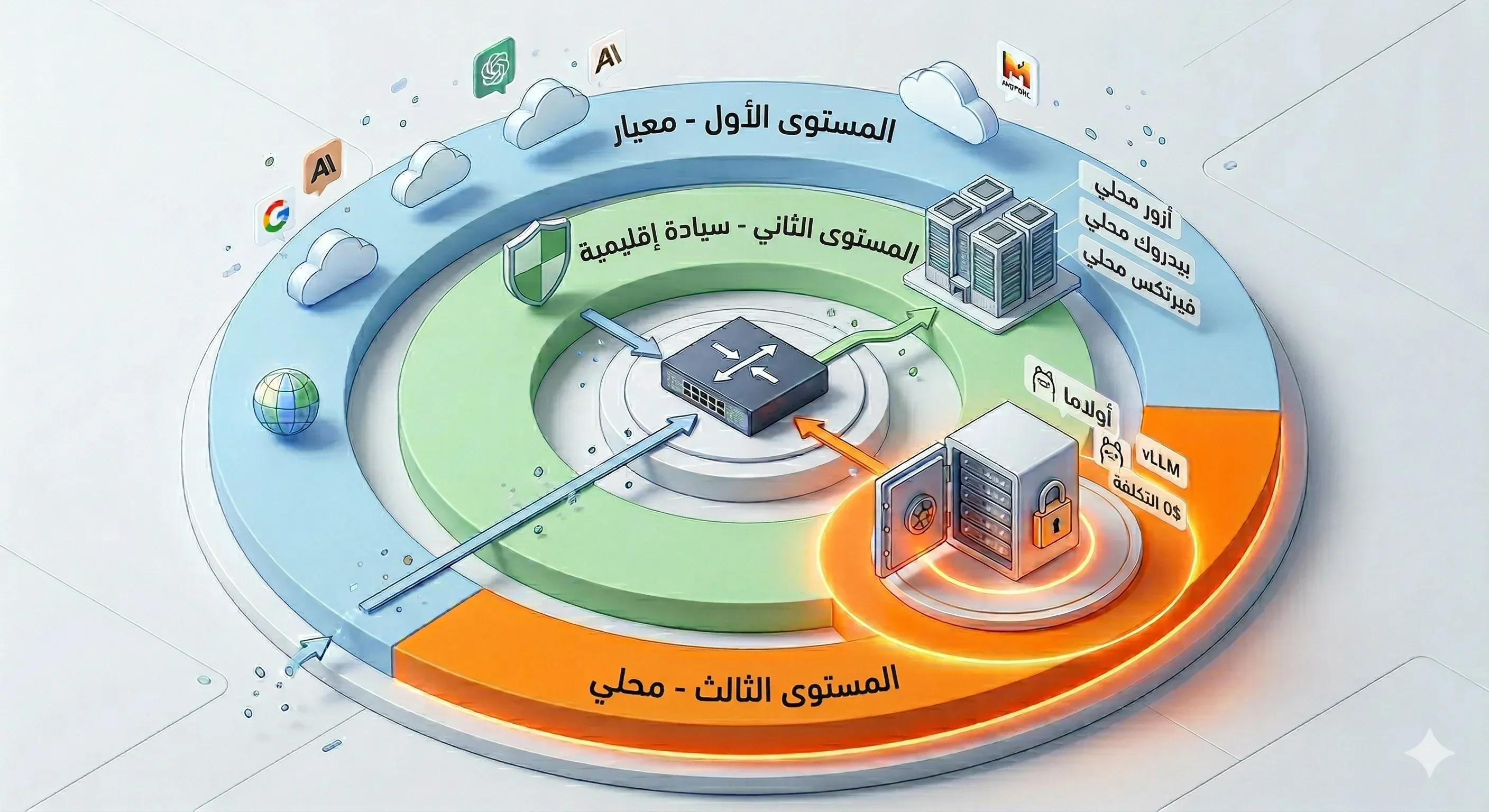
الموجِّه يقرر، أنت لا تفعل شيئًا
خوارزمية توجيه من 4 خطوات. لا تكوين يدوي. استرداد تلقائي إذا كان النموذج المفضل غير متاح.
محرك الذكاء الاصطناعي الأكثر اكتمالاً
مبني للفرق ذات متطلبات الامتثال التي لن تتنازل عن الأداء.
6 خطوات من مستندك إلى الإجابة
الهدف: أقل من 800 مللي ثانية P95. كل خطوة مستقلة وقابلة للمراقبة والتدقيق.
GPU سيادي: أسرع 2-4x
استنتاج GPU سيادي محسَّن. محركنا يسرِّع الإنتاجية لمضاعفة الأداء دون مغادرة بنيتك التحتية.
لا منافس يجمع الثلاثة مستويات
OpenAI وAzure وMistral يقدم كل منهم قطعة من اللغز. SkaLean هو المحرك الوحيد الذي يدمجها جميعًا، مع توجيه تلقائي وGPU سيادي وRAG أصلي وصفر عمولة.
| المعيار | OpenAI / Anthropic API | Azure OpenAI · Bedrock · Vertex | Open-source ذاتي | SkaLean AI Engine |
|---|---|---|---|---|
| سيادة البيانات | — خوادم أمريكية | ✓ المنطقة المختارة | ✓ على بنيتك التحتية | ✓ 3 مستويات تلقائية |
| عدد المزودين / النماذج | مزود واحد | 1-2 مزودين | نماذج مفتوحة فقط | ✓ 9 مزودين · 20+ نموذج |
| توجيه PII تلقائي | — | — | — | ✓ 18 نوعًا · درجة حساسية |
| حماية PII قبل إرسال LLM | — | — | — | ✓ إخفاء هوية + إعادة استبدال |
| TensorRT-LLM (تسريع 2-4x) | — | — | معقد DIY | ✓ أصلي · لا AIaaS منافسة |
| ضبط دقيق LoRA لكل عميل (NeMo) | ضبط OpenAI (مكلف) | ضبط Azure (مكلف) | DIY · لا عزل عملاء | ✓ NeMo · مجموعة بيانات مشفرة · معزولة |
| نموذج طبي سيادي | — | — | — | ✓ يتفوق على النماذج العامة في البيانات الصحية |
| RAG متكامل 6 خطوات | — | — | DIY · لا pipeline جاهزة | ✓ هجين + RRF + إعادة ترتيب + استشهادات |
| قاطع + استرداد تلقائي | — | — | — | ✓ استرداد متتالي تلقائي · 5 إعادة محاولة |
| OWASP LLM Top 10 | أساسي | جزئي | — | ✓ 10/10 · غير قابل للتعطيل |
| امتثال HIPAA قابل للتفعيل | — | ✓ BAA متاح (Azure، AWS) | — تكوين يدوي مطلوب | ✓ امتثال HIPAA قابل للتفعيل لكل عميل |
| عمولة الرموز | السعر العام | السعر العام + علاوة إقليمية | تكلفة بنية DIY | 0% السعر الدقيق للمزود |
| خدمة مُدارة | — خدمة ذاتية | — خدمة ذاتية | — كل شيء للتكوين | ✓ بناء · صيانة · خبرة SkaLean |
بياناتك لا تغادر منطقتك أبدًا
بنية تحتية محلية · امتثال تنظيمي أصلي · GDPR + CCPA · HIPAA قابل للتفعيل لكل مستأجر. SkaLean تضبط بنيتك التحتية السيادية وتديرها.
الأسئلة الشائعة
محرك الذكاء الاصطناعي يشغِّل المنظومة بأكملها
محرك الذكاء الاصطناعي السيادي هو العقل الذي يشغِّل Studio الذكاء الاصطناعي والأتمتة الذكية والمساعدين الذكيين، مستضاف محليًا، متوافق مع لوائحك، صفر اعتماد مفروض على السحابة.
تدفع مقابل الرموز. لا شيء أكثر.
SkaLean لا تأخذ أي عمولة على استدعاءات LLM. تُفوتر بالضبط بسعر المزود المعلن.
| المزود | النموذج | مدخل / 1K رمز | مخرج / 1K رمز | ملاحظات |
|---|---|---|---|---|
| OpenAI | gpt-4o | 0,0025 $ | 0,01 $ | 128K سياق · استدعاء الأداة |
| OpenAI | gpt-4o-mini | 0,00015 $ | 0,0006 $ | فائق السرعة · اقتصادي |
| OpenAI | gpt-4.1 / gpt-4.1-mini | 0,002 $ / 0,0001 $ | 0,008 $ / 0,0004 $ | أحدث جيل |
| Anthropic | claude-opus-4 | 0,015 $ | 0,075 $ | 200K سياق · الاستدلال |
| Anthropic | claude-sonnet-4 | 0,003 $ | 0,015 $ | توازن الأداء/التكلفة |
| Anthropic | claude-haiku-4.5 | 0,00025 $ | 0,00125 $ | سريع جدًا · تكلفة منخفضة |
| Mistral | mistral-large-2 | 0,002 $ | 0,006 $ | الاستضافة الأوروبية (باريس) |
| Mistral | mistral-small-3.1 | 0,0002 $ | 0,0006 $ | نموذج أوروبي مضغوط |
| gemini-2.5-pro | 0,00125 $ | 0,005 $ | سياق طويل جدًا | |
| gemini-2.5-flash | 0,00015 $ | 0,0006 $ | فائق السرعة · البث المستمر |
| المنصة | النموذج | مدخل / 1K رمز | مخرج / 1K رمز | السيادة |
|---|---|---|---|---|
| Azure OpenAI | gpt-4o / gpt-4o-mini | 0,0025 $ / 0,00015 $ | 0,01 $ / 0,0006 $ | المنطقة السيادية من اختيارك |
| Azure OpenAI | gpt-4.1 / gpt-4.1-mini | 0,002 $ / 0,0001 $ | 0,008 $ / 0,0004 $ | البيانات تبقى في بلدك |
| AWS Bedrock | Claude Opus 4 / Sonnet 4 | 0,015 $ / 0,003 $ | 0,075 $ / 0,015 $ | منطقة Bedrock السيادية |
| AWS Bedrock | Llama 3.1 70B / 8B | 0,00065 $ / 0,0003 $ | 0,00085 $ / 0,0006 $ | نموذج مفتوح عبر Bedrock |
| Vertex AI | Gemini 2.5 Pro / Flash | 0,00125 $ / 0,00015 $ | 0,005 $ / 0,0006 $ | منطقة Vertex السيادية |
| Vertex AI | Claude Sonnet 4 (via Vertex) | 0,003 $ | 0,015 $ | Anthropic عبر Google Model Garden |
| البنية التحتية | النماذج | مدخل / 1K رمز | مخرج / 1K رمز | الشروط |
|---|---|---|---|---|
| Ollama CPU | Llama وMistral وQwen والنماذج مفتوحة المصدر | 0 $ | 0 $ | مشمول في جميع الخطط |
| استدلال GPU | Llama 70B+، Qwen 72B، نماذج طبية متخصصة | مفوتر حسب الاستخدام | مفوتر حسب الاستخدام | مُهيَّأ من SkaLean · مشمول في الإعداد |
| LLM مخصص | ضبط دقيق LoRA على بياناتك | مشمول في الإعداد | مشمول في الإعداد | خطة Enterprise |
بنيتك التحتية للذكاء الاصطناعي، مُدارة من قِبَل SkaLean.
9 مزودين، 20+ نموذج، 3 مستويات سيادة. نشر في 5 إلى 20 يومًا.